|
Siyi Chen I am a PhD student in Electrical and Computer Engineering at University of Michigan-Ann Arbor (2022 - Present), advised by Prof. Qing Qu. My research interests encompass generative AI, multimodal foundation models, agentic systems, and robotics. Representative directions include diffusion models, vision-language models, embodied agency, and representation learning. I am interested in exploring their controllability, interpretability, and unification. Through industry internships, I have worked at NVIDIA's Learning and Perception Research Group with core mentors Jonathan Trembly, Valts Blukis, and Stan Birchfield, and at Sony AI America's Vision Foundation Model and Generative AI Team with Weiming Zhuang, Jingtao Li, and Lingjuan Lv. Prior to my PhD, I received a B.S.E. in Computer Science from University of Michigan-Ann Arbor, with a minor in Mathematics, and a B.S.E. in Electrical and Computer Engineering from Shanghai Jiao Tong University. During my undergraduate studies, I worked with Prof. David Fouhey and Dr. Shengyi Qian on 3D computer vision. I am looking for intern and full-time opportunities starting Fall 2026. Feel free to reach out, thank you! Email / Google Scholar / LinkedIn / Twitter / Github |

|
News1. [06/2026] Our paper Breaking the Curse of Dimensionality is accepted by JMLR 2026! 2. [06/2026] I joined NVIDIA as a Research Intern in the Learning and Perception Research Group! 3. [02/2026] Our paper SpaceTools is accepted by CVPR 2026! 4. [09/2025] One paper is accepted by NeurIPS 2025! 5. [05/2025] I joined NVIDIA as a Research Intern in the Learning and Perception Research Group! 6. [04/2025] I have received the Rackham Internship Fellowship! 7. [03/2025] I joined Sony AI America as a Research Intern in the Vision Foundation Model and Generative AI Team! 8. [03/2025] I have received the Rackham Predoctoral Fellowship! |
Work Experience |
|
|
NVIDIA, Learning and Perception Research Group, 06/2026 - Present. Research Intern. Host: Jonathan Trembly, Valts Blukis, Stan Birchfield, Mikaela Angelina Uy, Faisal Ladhak, Erwin Coumans, Luke Song, Hugo Hadfield, Alex Zook, Xuning Yang |
|
|
NVIDIA, Learning and Perception Research Group, 05/2025 - 05/2026. Research Intern. Host: Jonathan Trembly, Valts Blukis, Stan Birchfield, Mikaela Angelina Uy, Faisal Ladhak, Erwin Coumans, Luke Song, Hugo Hadfield, Alex Zook, Xuning Yang |
|
|
Sony AI America, Vision Foundation Model and Generative AI Team, 03/2025 - 05/2025. Research Intern. Host: Jingtao Li, Weiming Zhuang, Lingjuan Lv |
Publicaions |
|
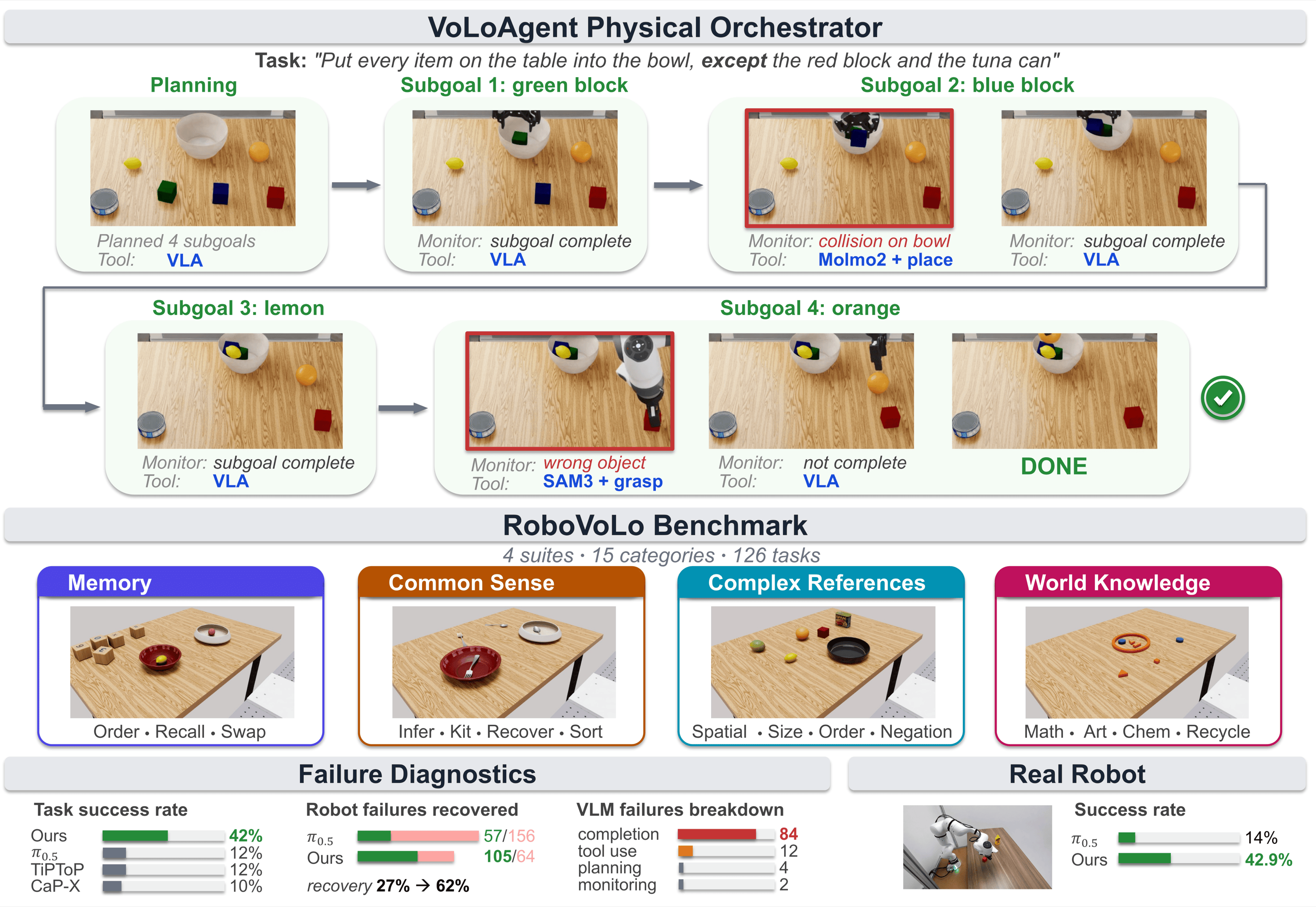
VoLo: A Physical Orchestrator for Open-Vocabulary Long-Horizon Manipulation
Siyi Chen, Hugo Hadfield, Alex Zook, Mikaela Angelina Uy, Chan Hee Song, Erwin Coumans, Xuning Yang, Faisal Ladhak, Qing Qu, Stan Birchfield, Jonathan Tremblay, Valts Blukis Preprint, 2026 website / paper We frame open-vocabulary long-horizon manipulation as physical orchestration and present VoLoAgent, a VLM agent that plans, monitors, and recovers by steering a VLA/WAM as an interruptible tool alongside perception models and grasp/place primitives. We also introduce RoboVoLo, a high-fidelity benchmark of 126 tasks across common sense, memory, complex references, and world knowledge, to support the evaluation of open-vocabulary long-horizon robot manipulation. |
|
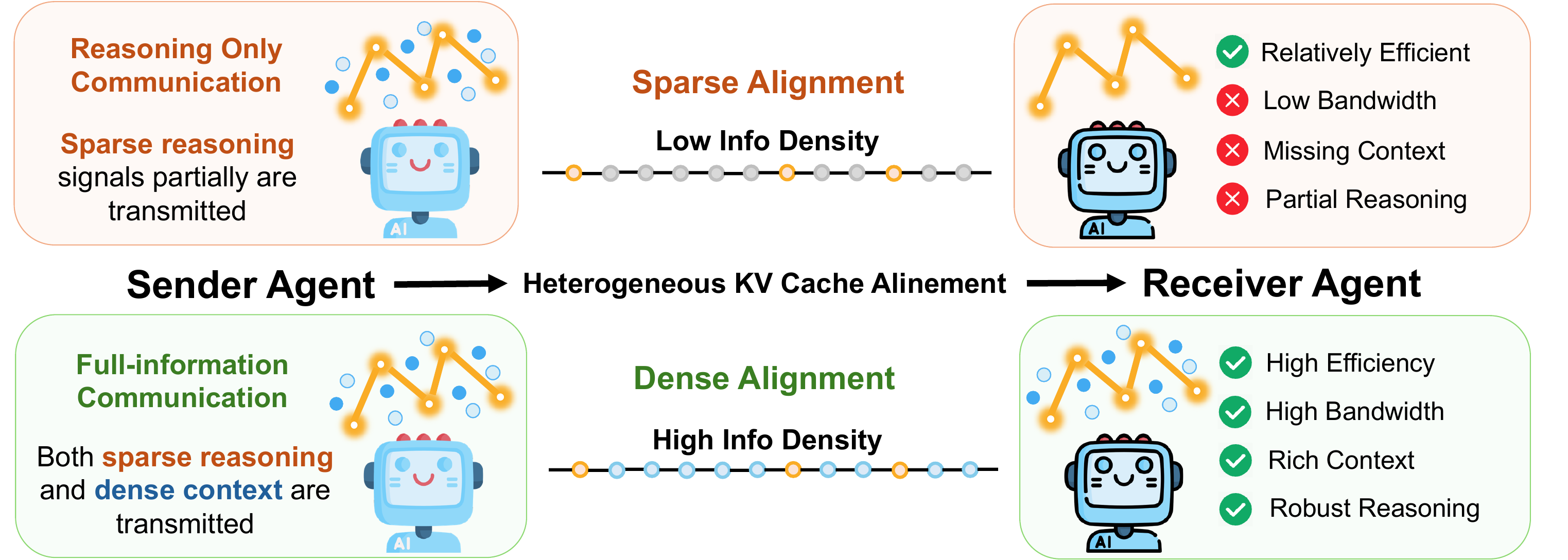
See What I See, Know What I Think: Dense Latent Communication Across Heterogeneous Agents
Siyi Chen, Xiaoyan Zhang, Meng Wu, Jonathan Tremblay, Valts Blukis, Stan Birchfield, Rene Vidal, Alvaro Velasquez, Sijia Liu, Qing Qu Preprint, 2026 website / paper We propose dense alignment for heterogeneous KV-cache communication, enabling agents with different model architectures to transfer both contextual knowledge and reasoning signals. |
|
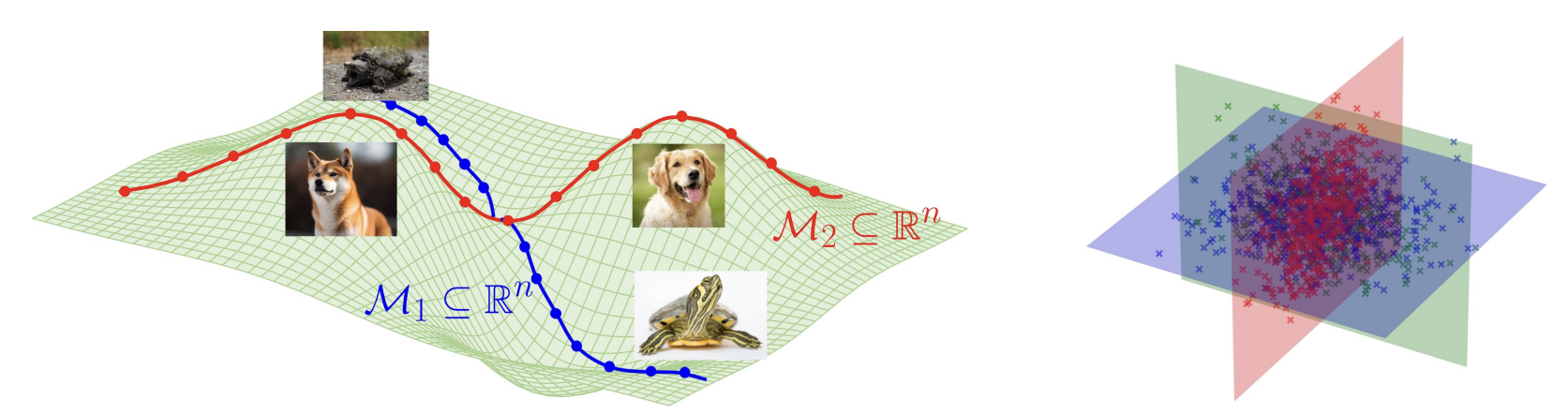
Breaking the Curse of Dimensionality: Diffusion Models Efficiently Learn Low-Dimensional Distributions
Peng Wang*, Huijie Zhang*, Zekai Zhang, Siyi Chen, Yi Ma, Qing Qu JMLR, 2026 code / paper We provide theoretical insights into the connection between diffusion models and subspace clustering, shedding light on the transition from memorization to generalization and how diffusion models break the curse of dimensionality. |
|
SpaceTools: Tool-Augmented Spatial Reasoning via Double Interactive RL
Siyi Chen, Mikaela Angelina Uy, Chan Hee Song, Faisal Ladhak, Adithyavairavan Murali, Qing Qu, Stan Birchfield, Valts Blukis, Jonathan Tremblay CVPR, 2026 website / code / paper SpaceTools empowers VLMs with vision and robotic tools for spatial reasoning via Double Interactive Reinforcement Learning (DIRL), enabled by our Toolshed infrastructure. Achieves state-of-the-art performance on spatial reasoning benchmarks and enables precise real-world robot manipulation. |
|
|
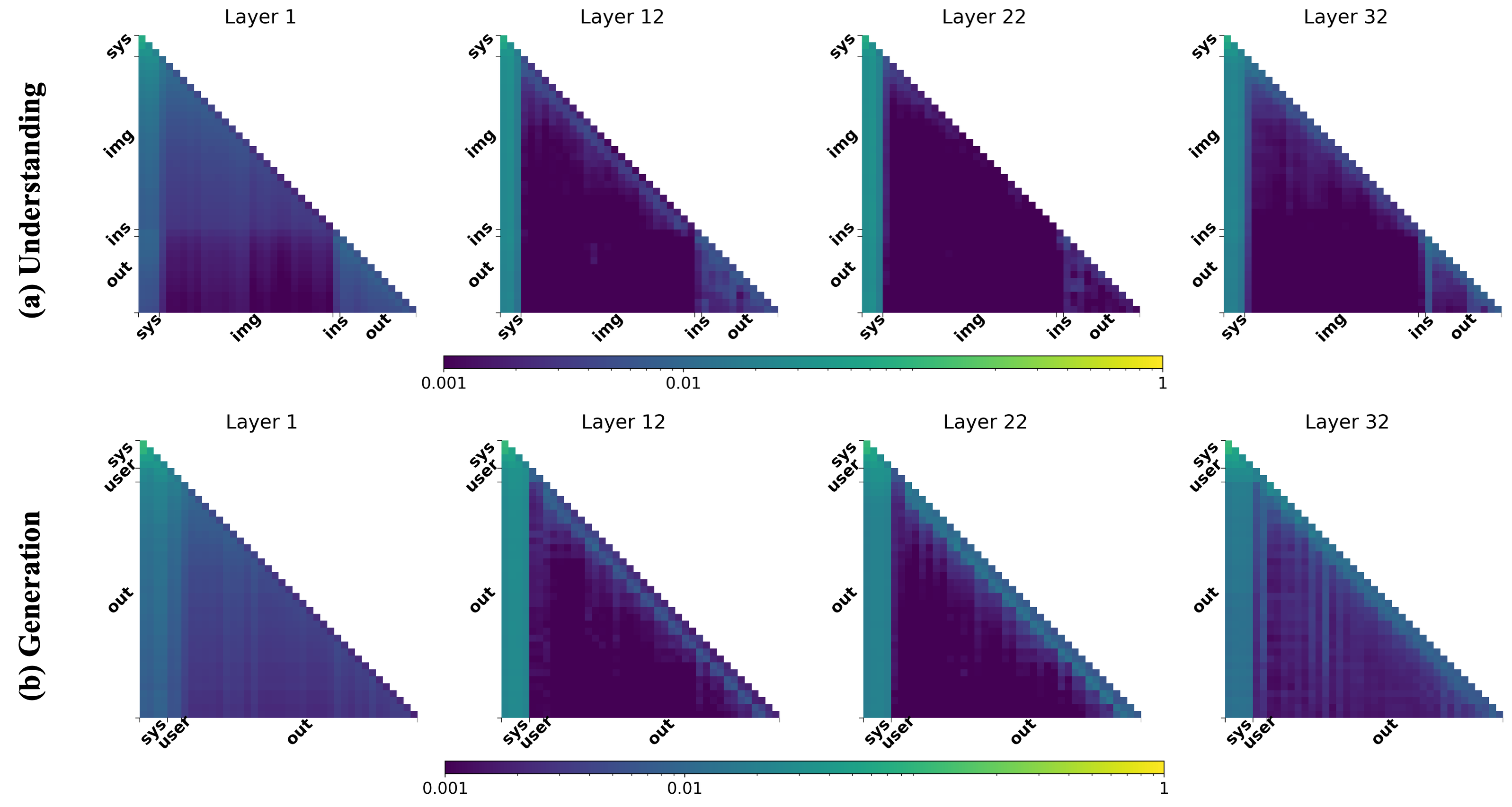
On the Limits of Token Reduction for Efficient Unified Vision Language Training
Siyi Chen, Weiming Zhuang, Jingtao Li, Lingjuan Lv CVPRW, 2026 website / code / paper We study token-reduction-based acceleration for unified VLM training, uncover a fundamental asymmetry in visual token usage across depth, and reveal that naive task-specific token dropping breaks cross-task synergy in joint optimization. |
|
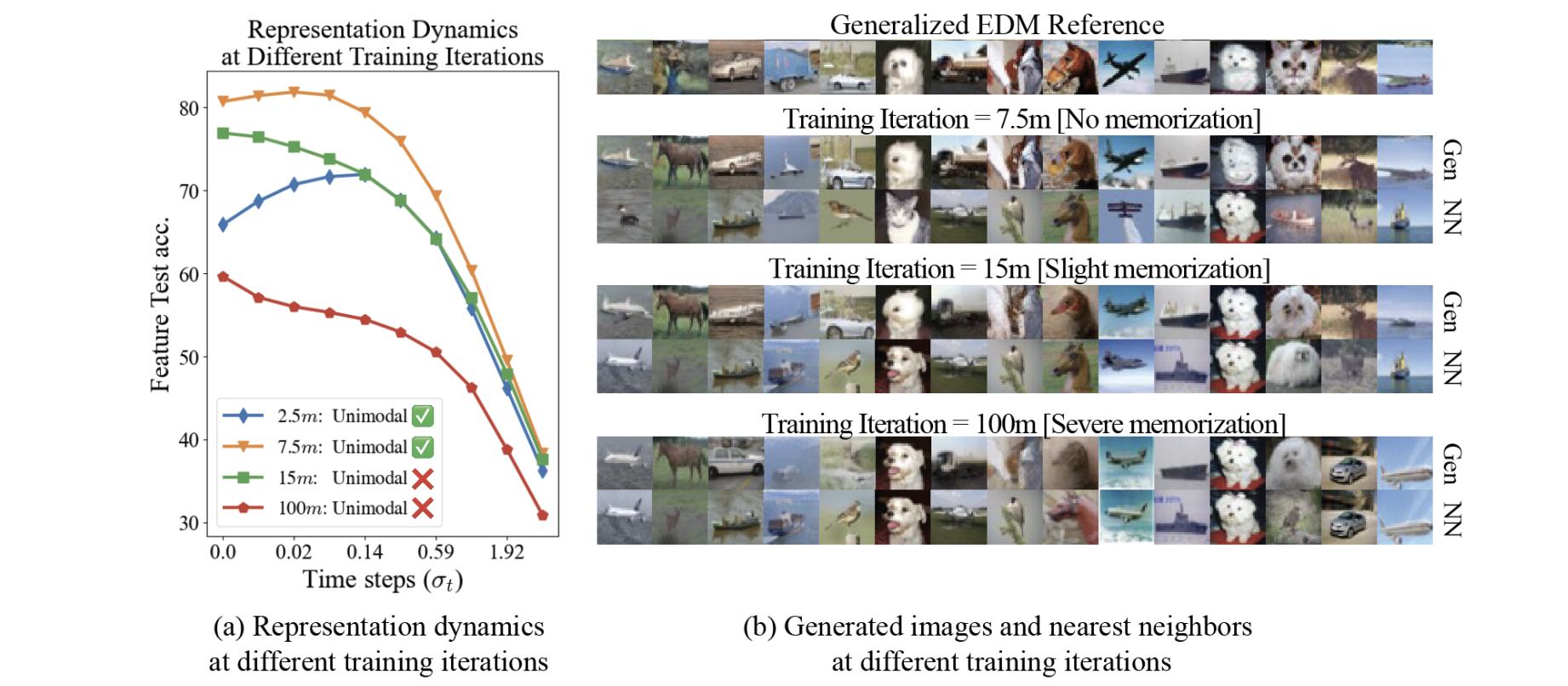
Understanding Representation Dynamics of Diffusion Models via Low-Dimensional Modeling
Xiao Li*, Zekai Zhang*, Xiang Li, Siyi Chen, Zhihui Zhu, Peng Wang, Qing Qu NeurIPS, 2025 paper We investigate why diffusion models excel at representation learning despite being designed for generation. We show that unimodal representation dynamics—where feature quality peaks at an intermediate noise level—emerge when the model captures the data distribution, and reliably indicate generalization versus memorization. |

|
The Dual Power of Interpretable Token Embeddings: Jailbreaking Attacks and Defenses for Diffusion Model Unlearning
Siyi Chen, Yimeng Zhang, Sijia Liu, Qing Qu Preprint, 2025 website / code / paper We introduce a novel framework for auditing and improving the robustness of unlearned diffusion models by proposing an interpretable subspace attack, that reveals latent vulnerabilities and inspires a corresponding projection-based defense to surgically remove them. |
|
Understanding Generalization in Diffusion Models via Probability Flow Distance
Huijie Zhang, Zijian Huang, Siyi Chen, Jinfan Zhou, Zekai Zhang, Peng Wang, Qing Qu Preprint, 2025 website / paper We propose probability flow distance (PFD), a theoretically grounded and computationally efficient metric to measure distributional generalization. By using PFD under a teacher-student evaluation protocol, we empirically uncover several key novel generalization behaviors in diffusion models. |
|
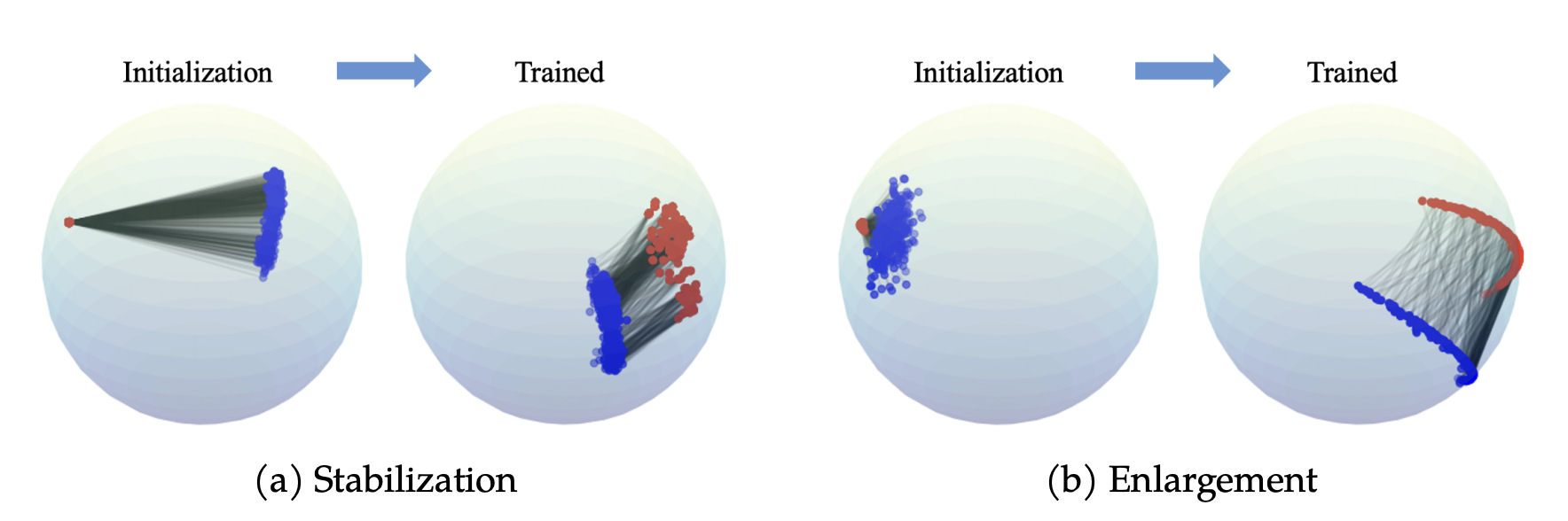
Explaining and Mitigating the Modality Gap in Contrastive Multimodal Learning
Can Yaras*, Siyi Chen*, Peng Wang, Qing Qu CPAL, 2025 website / code / paper We study gradient flow to explain modality gap in CLIP, and propose new methods to mitigate modality gap while improving model performance. |

|
Exploring Low-Dimensional Subspaces in Diffusion Models for Controllable Image Editing
Siyi Chen*, Huijie Zhang*, Minzhe Guo, Yifu Lu, Peng Wang, Qing Qu NeurIPS, 2024 website / code / paper We enable localized, transferable, linear, and composable image editing on diffsion models by exploring their low-rank and locally linear semantic spaces. |
|
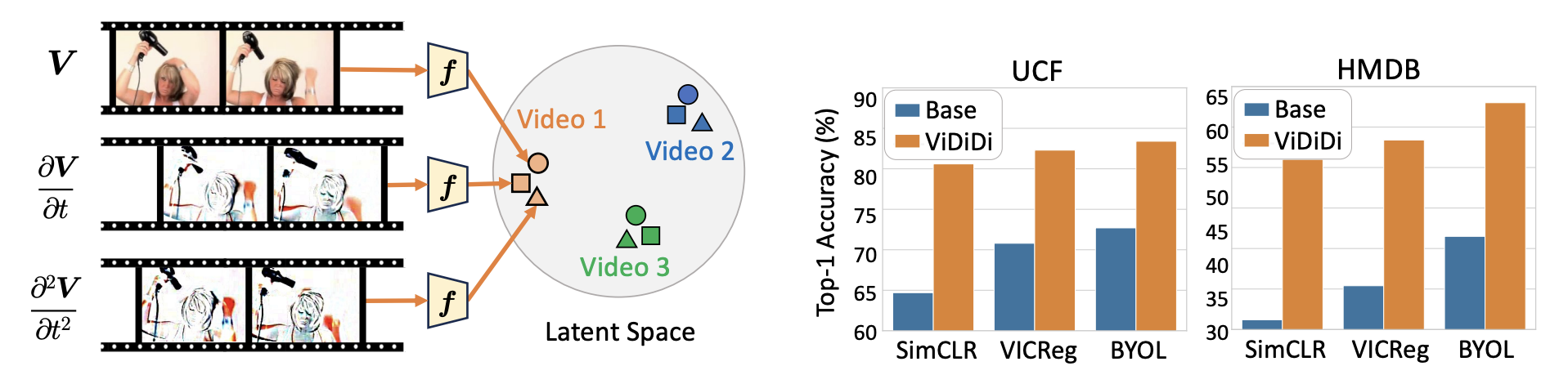
Unfolding Videos Dynamics via Taylor Expansion
Siyi Chen, Minkyu Choi, Zesen Zhao, Kuan Han, Qing Qu, Zhongming Liu Preprint, 2024 paper Inspired by physical motion, we unfold a video clip via Taylor expansion and design an alternative algorithm for self-supervised video representation learning. Our proposed method can steer the model to dynamic parts in the video. |
|
Understanding 3D Object Articulation in Internet Videos
Shengyi Qian, Linyi Jin, Chris Rockwell, Siyi Chen, David Fouhey CVPR, 2022 website / code / paper We propose to investigate detecting and characterizing the 3D planar articulation of objects from ordinary videos. |
Teaching |
 |
Graduate Student Instructor, EECS 559 Optimization, 2024 & 2025 Undergraduate Instructional Assistant, EECS 442 Computer Vision, 2022 |
Explorations & earlier projects |
|
Self-designed Game: Asylum 7
Siyi Chen, Yigao Fang, Dawei Wang, Zhongqian Duan, Ruipu Li Course Project, University of Michigan, 2022 Advisor: Austin Yarger Play it here As a team of five, we designed a horror game, Asylum 7, with Unity. |
|
Generate 3D Indoor Synthetic Dataset
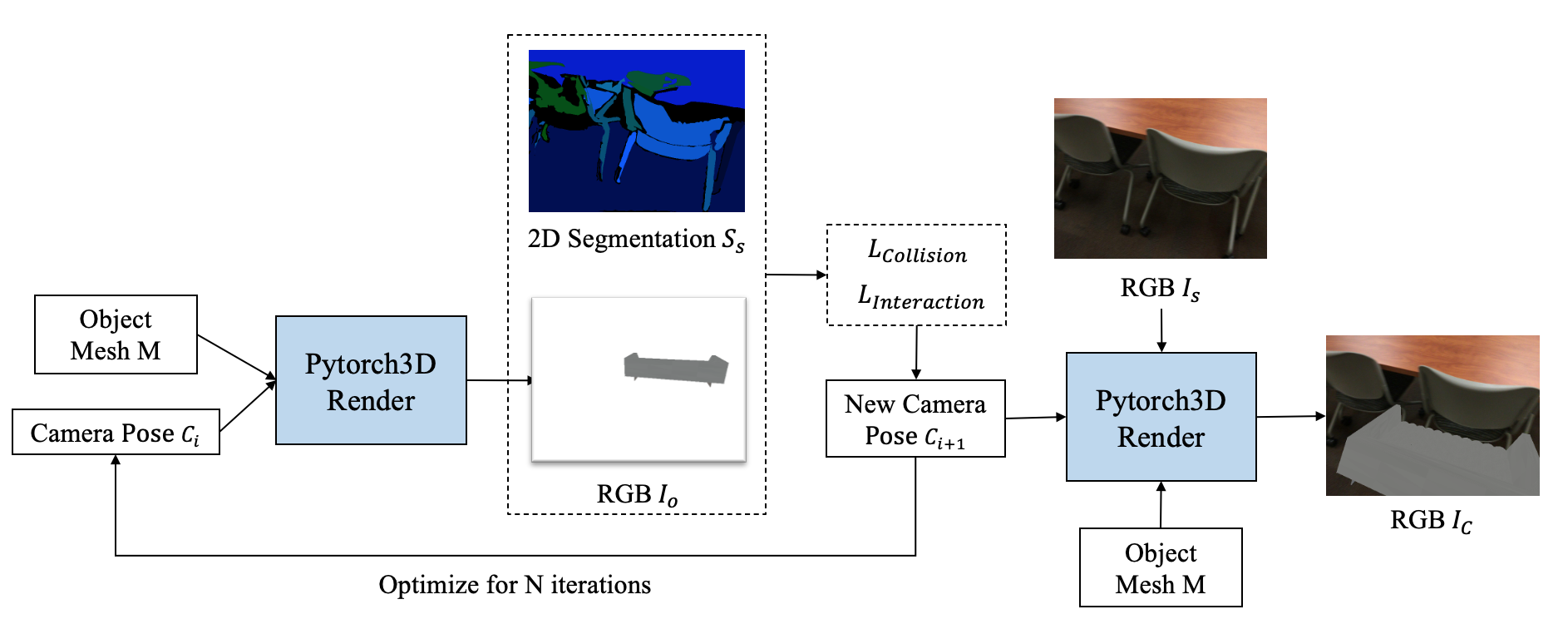
Siyi Chen 3D Computer Vision Research, University of Michigan, 2022 Advisor: Shengyi Qian, David Fouhey code We generate 3D synthetic video dataset containing a moving object and a scene. The pose and position of the object is optimized via a differential render. |
|
Combined Understanding of 3D Plane Articulation and Partial Human Pose Estimation
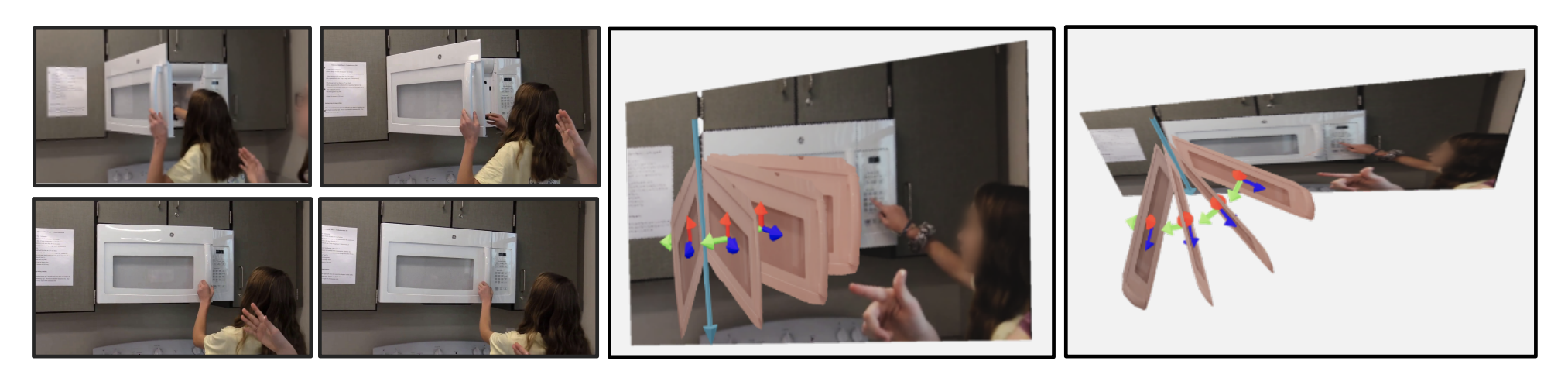
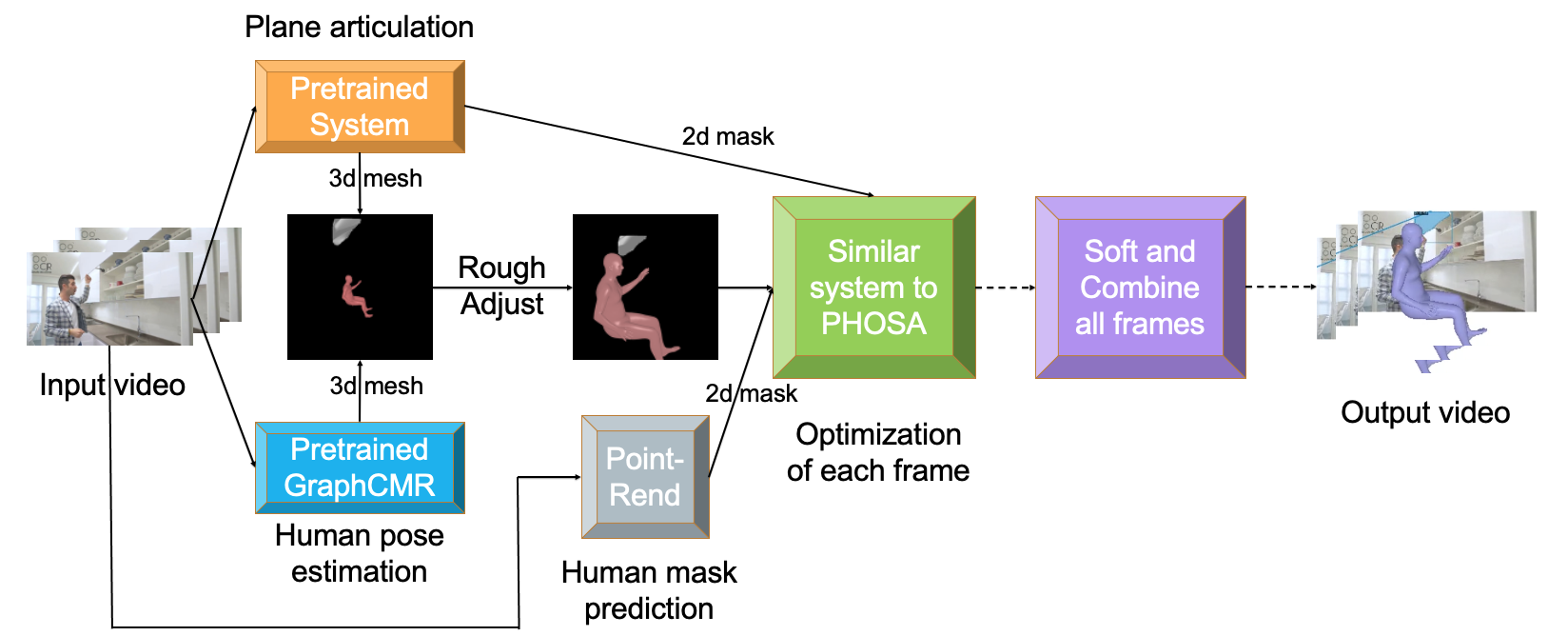
Siyi Chen 3D Computer Vision Research, University of Michigan, 2021 Advisor: Shengyi Qian, David Fouhey code / poster We predict 3D partial human poses as SMPL meshes, predict 2D plane masks as well as 3D articulation information, and use a differential render to optimize the position and pose of the person considering 3d space interactions. |
|
Convex Presentations of Translation Surfaces
Siyi Chen, Andrew Keisling, Kaiwen Lu, Brendan Nell Computational Geometry Research, University of Michigan, 2021 Advisor: Chaya Norton, Paul Apisa code / poster / paper We designed and implemented beta versions of enumerating origamis in H(2) and utilized SageMath to implement the convexity test presented by Lelievre and Weiss. |

|
Design A Roller Coaster
Siyi Chen, Yigao Fang, Qi Shen Gold Medal Winner (Top 2%) , The University Physics Competition 2019 paper We devise a rule to evaluate the safety and difficulty level of roller coasters, propose a novel roller coster model, and give a through analysis based on Euler's method and natural axes. |
|
This webpage is based on Jon Barron. |