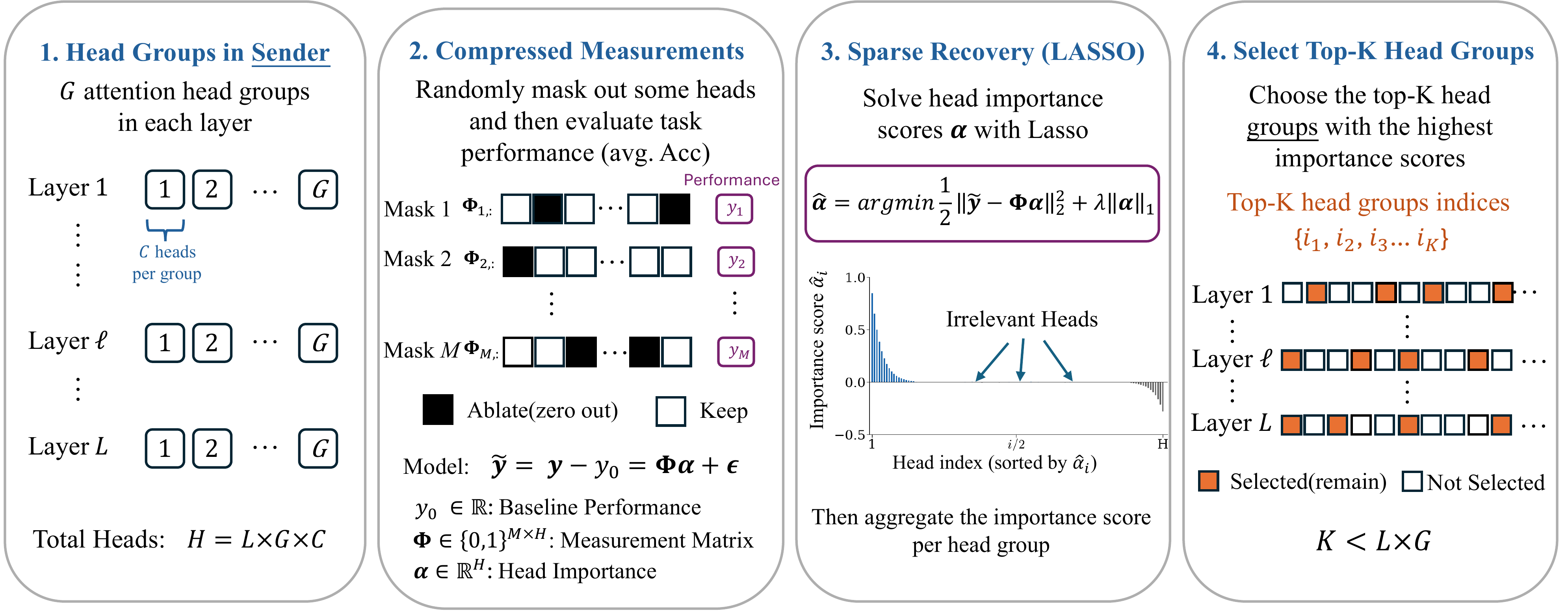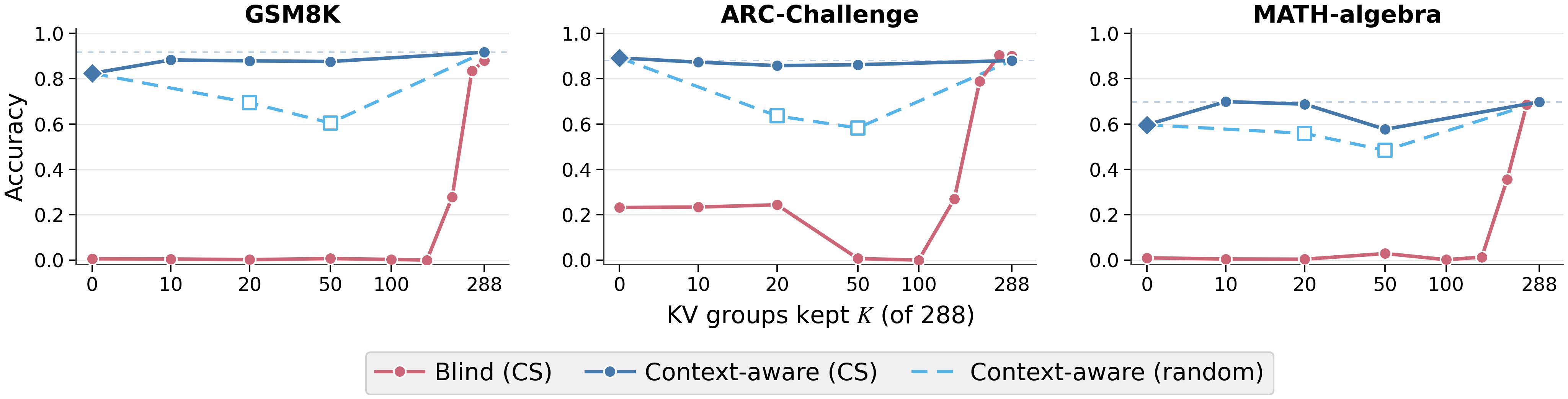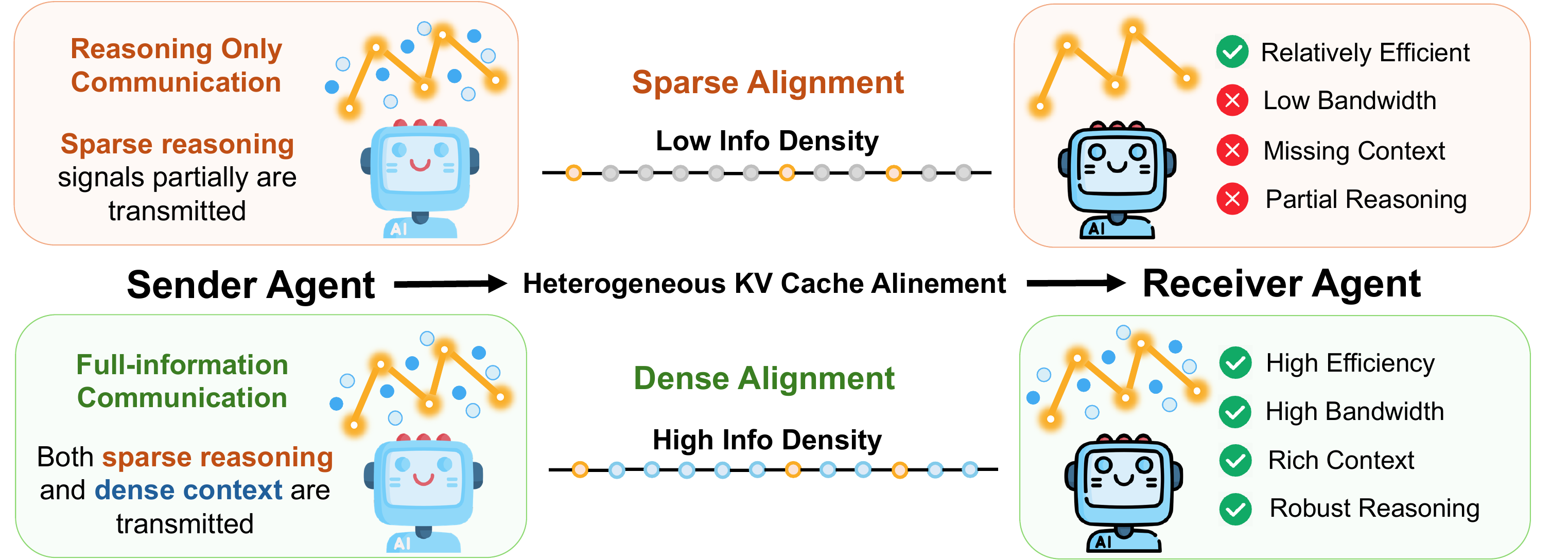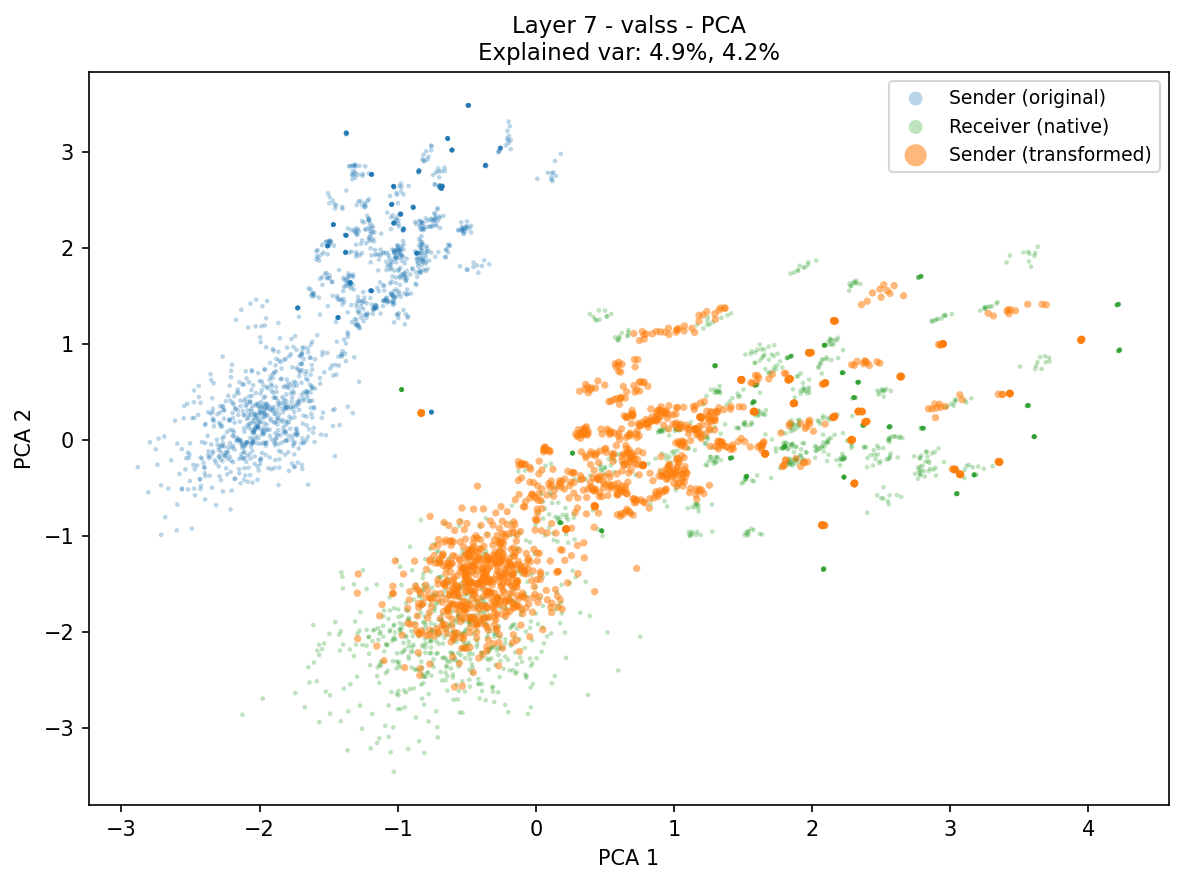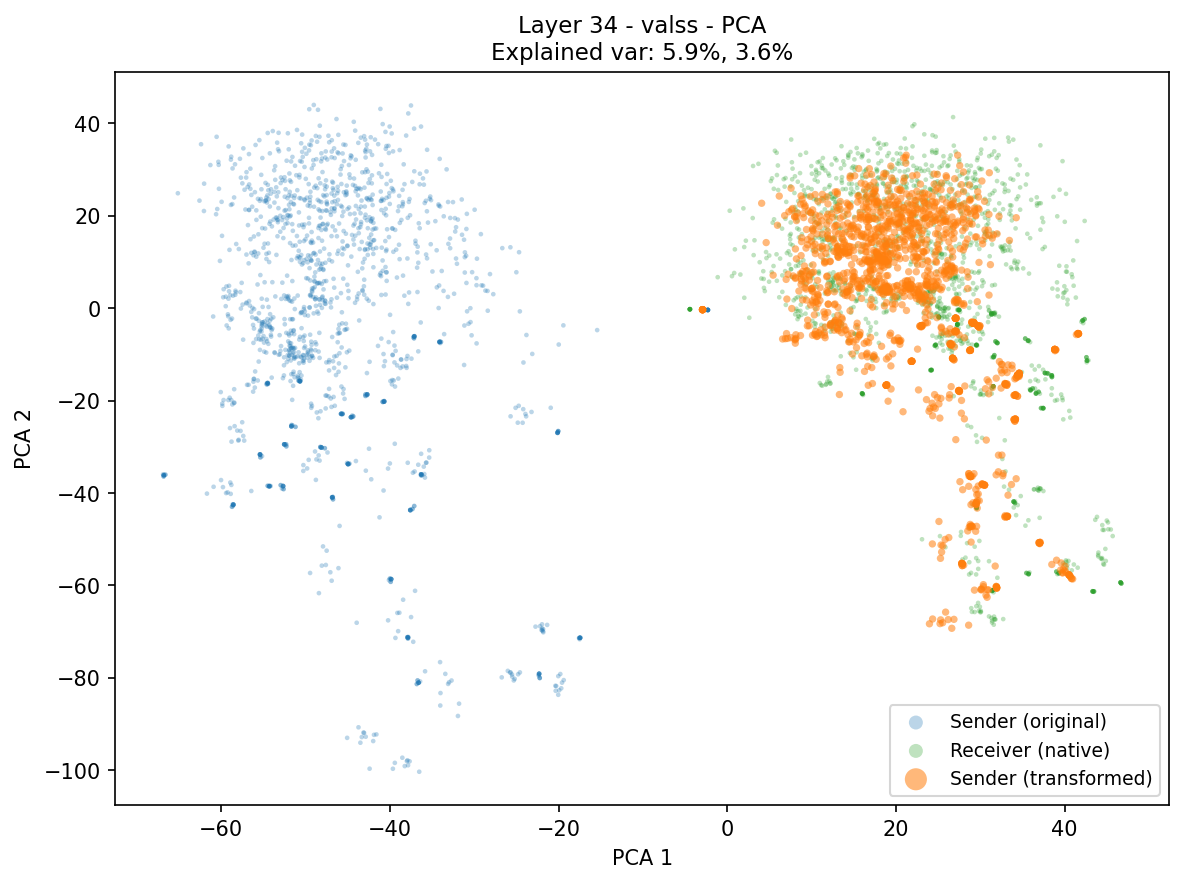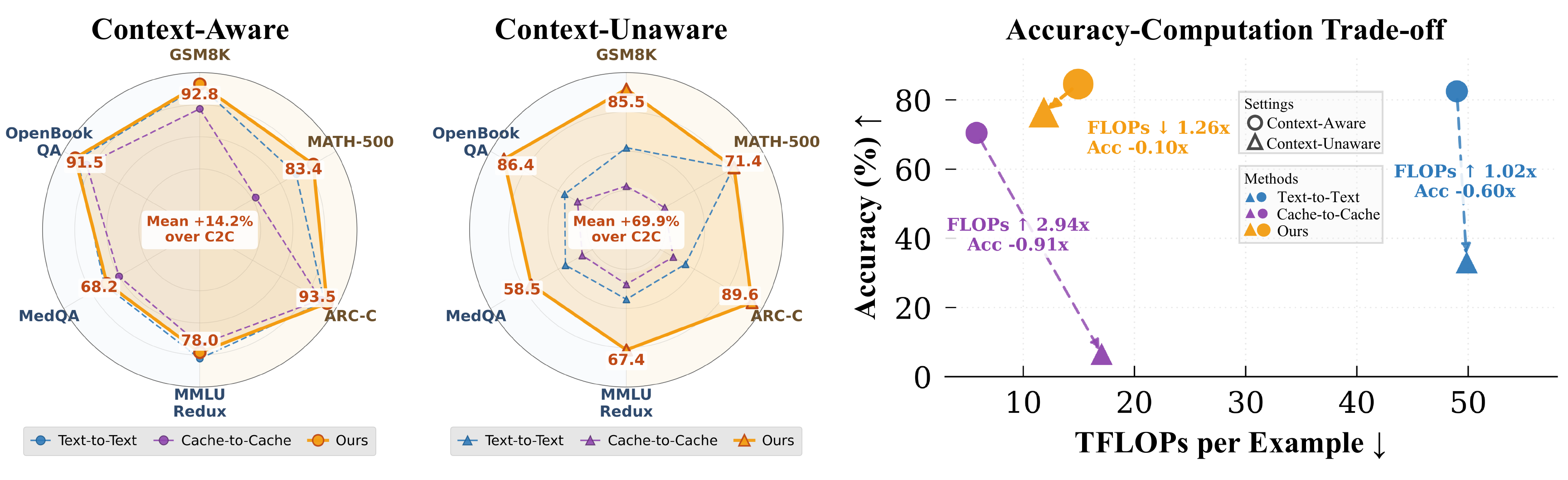
Multi-agent systems communicate mostly through text, paying a lossy and expensive decode and re-encode cost. KV-cache communication is a promising alternative, yet most prior work is homogeneous, using duplicate copies of the same model, and avoids the central challenge of cross-model latent alignment; existing heterogeneous methods are also restrictive, typically assuming shared input and using transferred caches mainly for steering. We study a more fundamental question: can heterogeneous agents be aligned well enough to perform real "mind reading" and transfer both what one agent sees and how it thinks? Our information-structure analysis reveals a duality: context-aware transfer is driven by sparse reasoning signals, while context-unaware transfer, where the receiver sees no input, requires dense contextual knowledge preservation. Motivated by this, we propose dense alignment for heterogeneous KV-cache communication via a lightweight cross-model cache transformation and two-phase training: reconstruction followed by generation. Across all six directions of {Qwen3-4B, 8B, 14B} and six in-domain and out-of-domain benchmarks, our method outperforms prior heterogeneous baselines, matches or exceeds text communication in context-aware settings at roughly 2 to 3× lower compute, and remains effective in context-unaware transfer where prior methods collapse.
@misc{chen2026denselatentcommunication,
title={See What I See, Know What I Think: Dense Latent Communication Across Heterogeneous Agents},
author={Siyi Chen and Xiaoyan Zhang and Meng Wu and Jonathan Tremblay and Valts Blukis and Stan Birchfield and Rene Vidal and Alvaro Velasquez and Sijia Liu and Qing Qu},
year={2026},
note={Preprint}
}