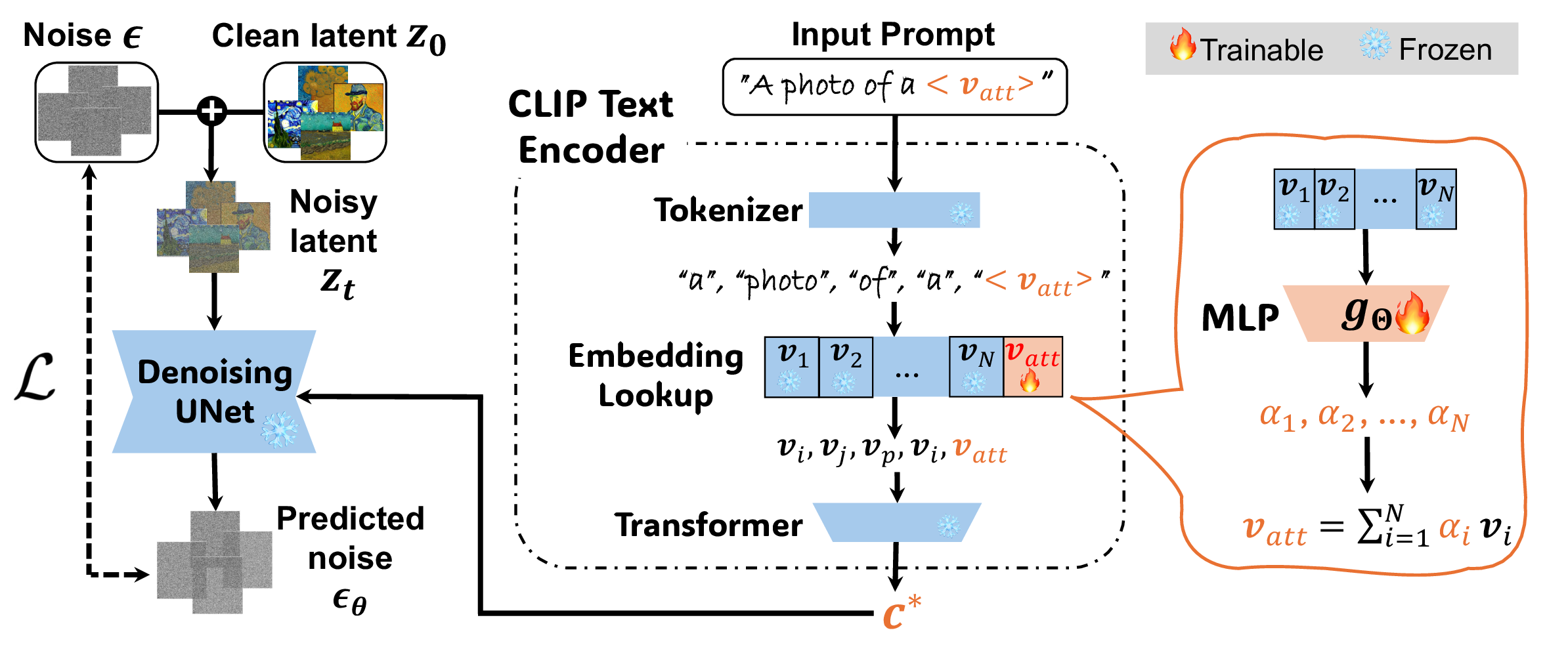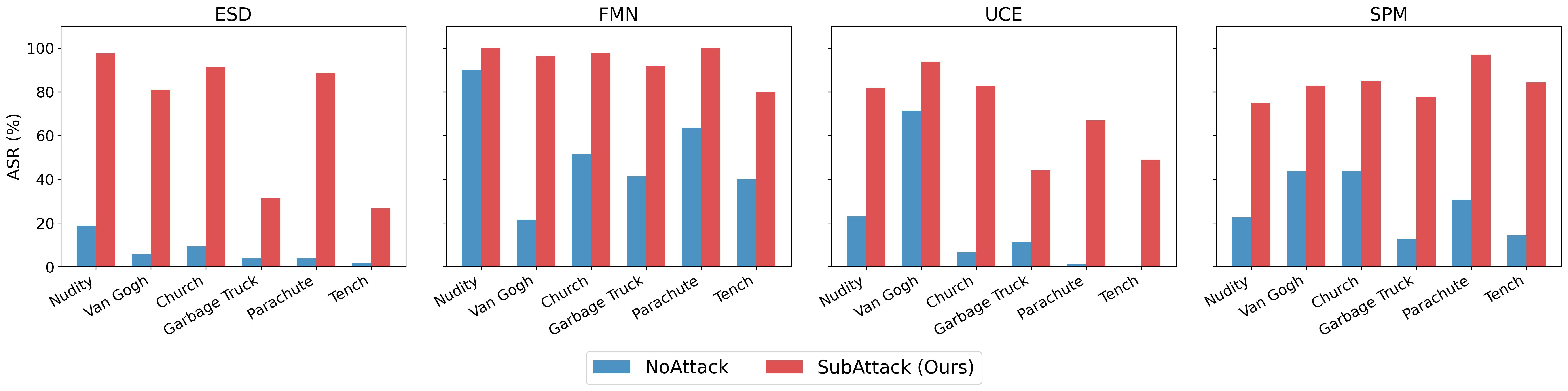
Diffusion models excel at generating high-quality images but can memorize and reproduce harmful concepts when prompted. Although fine-tuning methods have been proposed to unlearn a target concept, they struggle to fully erase the concept while maintaining generation quality on other concepts, leaving models vulnerable to jailbreak attacks. Existing jailbreak methods demonstrate this vulnerability but offer limited insight into how unlearned models retain harmful concepts, limiting progress on effective defenses. In this work, we show that the erased concept persists as a coherent, human-interpretable linear residual subspace of the token embedding space, and that both an attack and a defense follow directly from this structure. We introduce SubAttack, a novel jailbreaking attack that reads out this subspace by learning an orthogonal set of attack token embeddings, each a linear combination of human-interpretable textual elements, revealing that unlearned models still retain the target concept through related textual components. Furthermore, our attack is also more powerful and transferable across text prompts, initial noises, and unlearned models than prior attacks. Conversely, projecting out the same subspace yields SubDefense, a lightweight plug-and-play defense mechanism that suppresses the residual concept in unlearned models. SubDefense provides stronger robustness than existing defenses while better preserving safe generation quality. Extensive experiments across multiple unlearning methods, concepts, and attack types demonstrate that our approach advances both understanding and mitigation of vulnerabilities in diffusion unlearning.
@article{chen2025dualpower,
title={The Dual Power of Interpretable Token Embeddings: Jailbreaking Attacks and Defenses for Diffusion Model Unlearning},
author={Chen, Siyi and Zhang, Yimeng and Liu, Sijia and Qu, Qing},
journal={arXiv preprint arXiv:2504.21307},
year={2025}
}