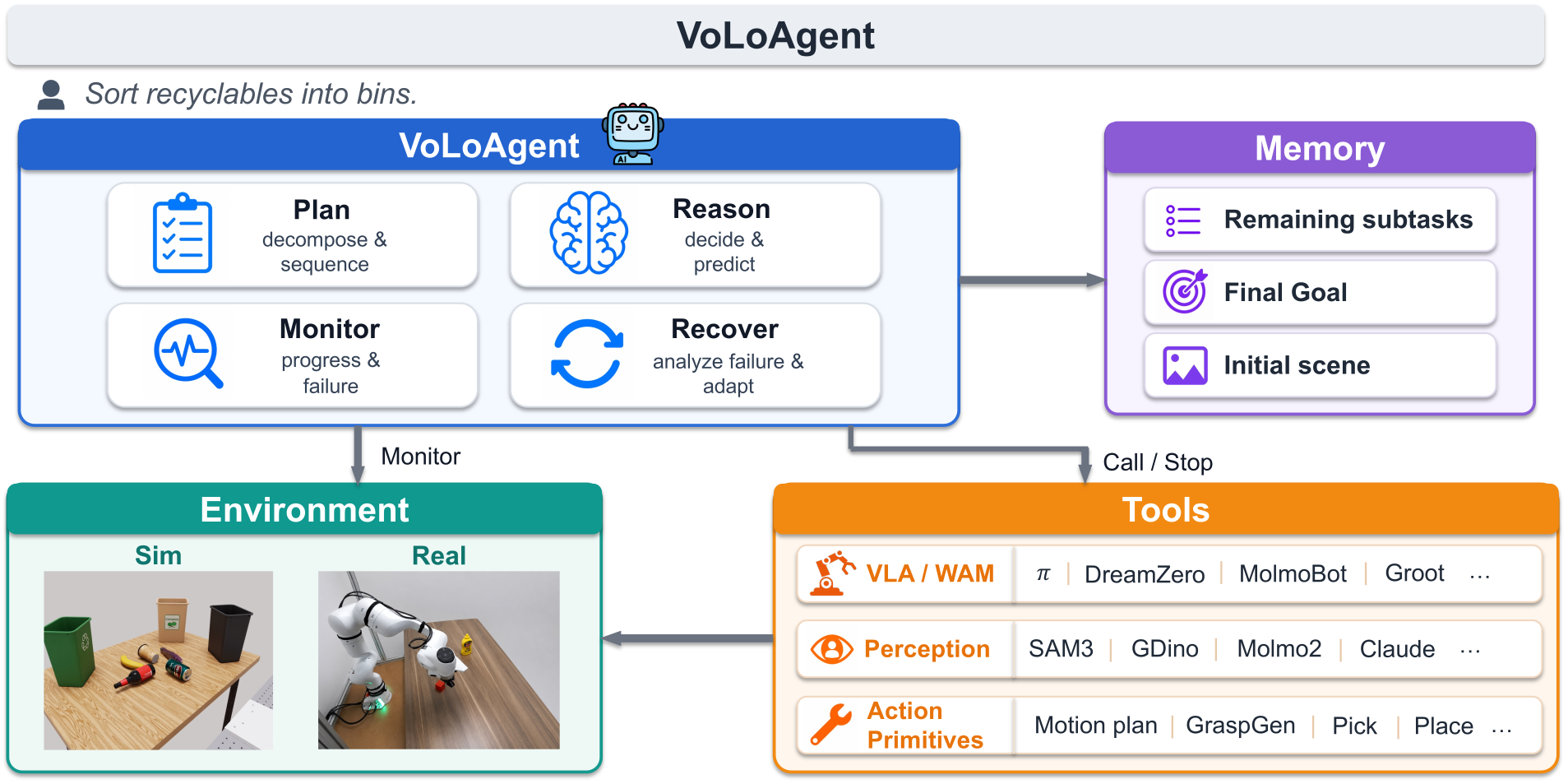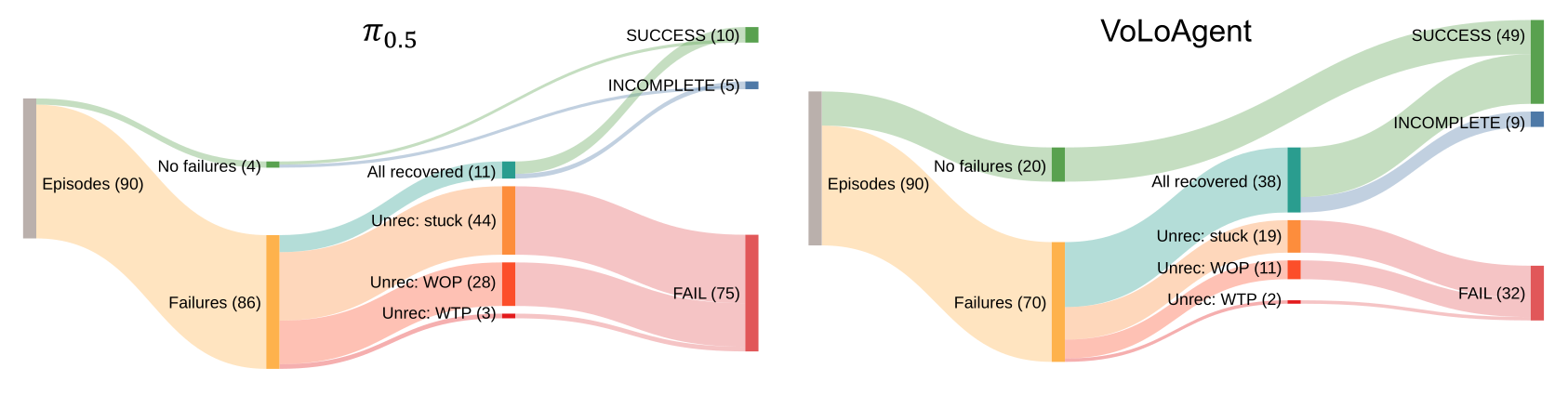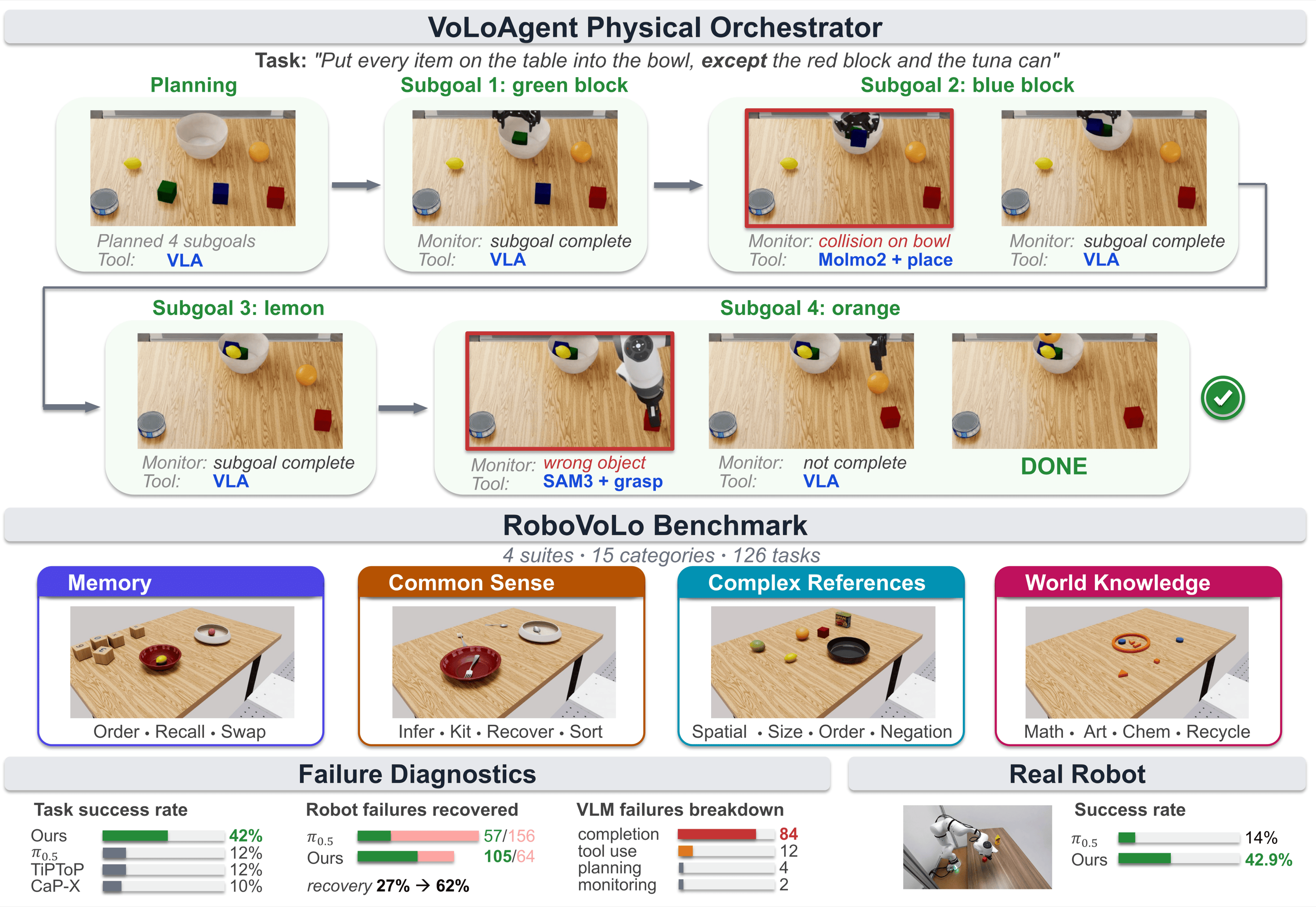
VoLo overview. VoLoAgent plans, monitors (e.g., subgoal complete), and uses tools (e.g., VLA, SAM3) to act and recover from failures (e.g., wrong object). RoboVoLo is a high-fidelity benchmark for evaluating and diagnosing open-vocabulary long-horizon manipulation.